ERP沙盘场景中的杜邦分析适用性验证
本页聚焦课题中的一个关键子任务:验证传统杜邦指标是否可作为 ERP 沙盘策略优化与后续智能决策训练的参考信号。 ERP(Enterprise Resource Planning)本质是通过统一数据链路去协同采购、生产、销售与财务等企业资源。 ERP 沙盘则是在可控环境中把企业经营压缩为多季度对抗决策过程,核心是用有限信息做资金、产能、市场与风险选择。 基于老师提供的横跨8年的校内沙盘数据,结论是:杜邦框架在该场景下整体几乎不可用。 无论采用传统算法还是智能算法,在此场景下,只要把杜邦指标当作核心优化依据,都容易与真实评分目标错位并引发策略灾难。
在课题研讨会中企业高管对“黑箱决策难以追溯其根因、AI决策责任难以划分”的普遍顾虑,并结合个人对企业运营中的牵制因素过于多、复杂(特别是商业运营环境中的“暴雷”等突发因素以及国内的营商环境),智能体难以收敛的思考,我判断该课题路径在真实企业中短期难落地,最多更适合低风险的校园沙盘场景,但这又背离了课题的命题初衷,一个国家级课题终究会降级为一个象牙塔里的小玩具;这也是很多智能体产品,难以真正投入产业应用的原因之一;当然本人在课题组中的工作不止于此数据分析,也进行了COZE平台的智能体尝试(受限于LLM的截断问题,效果一般,GUI式的智能体开发也基本是泡沫产业); 综合以上,本人在完成该阶段验证后退出此项目。
通过这一国家级课题项目,我窥见了科研的冰山一角,让我更加渴望去脚踏实地做工程,真正去磨练自身的技术;本人在本科阶段尚无论文产出,更多受限于机会与方法引导不足,而非研究意愿不足;若研究生阶段获得导师系统指导,我会把更多热情与精力投入到可复现、可落地并且真正有应用价值的实践探究中。。研究背景与课题定位
在国家社科基金一般项目“人工智能大模型的可持续发展能力评估与提升路径研究”中, ERP 沙盘数据分析是支撑智能决策研究的基础环节之一。本人在项目中的工作重点不是开发智能体产品, 而是去论证一个更前置的问题:传统财务指标(杜邦指标)是否具备作为训练参考量的稳定价值。
该课题属于社科类研究,对电子信息本科背景而言是一次跨专业切换。 有一个客观条件是,父母均为商科本科背景且长期从事外贸相关工作,家庭讨论中常涉及成本、现金流与风险控制,这也让我面对商科议题时并不发怵。
研究问题
在 ERP 沙盘竞赛中,杜邦分析能否同时用于排名提升与破产风险控制(主要考虑其相关性),并作为策略指导工具。
数据范围
统计样本为 115 支队伍、30 场比赛,分析数据由老师提供,是从2018年到2022年的校内沙盘模拟赛、热身赛等学生操作的详细数据。
验证性质
这是课题中的指标验证步骤,目标是识别可用信号与无效信号,而非单纯成败判断。
输出价值
核心价值是识别此分析方法的有效性,避免后续传统算法或智能算法继续把杜邦指标当作主驱动信号。
杜邦框架与ERP沙盘规则差异
传统杜邦分析以 ROE = 净利率 × 总资产周转率 × 权益乘数 为核心, 偏向衡量单期相对收益率;而 ERP 沙盘采用百树规则,核心目标是累积财富与综合发展潜力。
杜邦框架:ROE = 净利率 × 总资产周转率 × 权益乘数
ERP沙盘规则:总成绩 = 所有者权益 × (1 + 企业综合发展潜力/100)| 对比维度 | 传统杜邦分析 | ERP沙盘百树规则 | 对建模的影响 |
|---|---|---|---|
| 目标函数 | 相对收益率(ROE) | 绝对财富值(所有者权益)与发展潜力 | 直接最大化 ROE 不等价于最大化最终排名 |
| 时间尺度 | 单期经营能力 | 5-6年累积经营结果 | 短期高 ROE 可能对应中后期高风险 |
| 样本分布 | 默认企业财务结构稳定 | 65.2% 队伍破产,异常值密集 | 需拆分破产/未破产群体进行分层建模 |
关键验证结果
结果 1:全样本中 ROE 与排名无显著相关
| 指标 | 与排名相关系数 | 统计显著性 | 解读 |
|---|---|---|---|
| ROE | r = 0.158 | p = 0.092(不显著) | ROE 越高排名不一定越好,整体解释力弱 |
| 净利率 | r = -0.136 | p = 0.148(不显著) | 全样本层面无稳定相关 |
| 总资产周转率 | r = 0.114 | p = 0.225(不显著) | 对排名预测作用有限 |
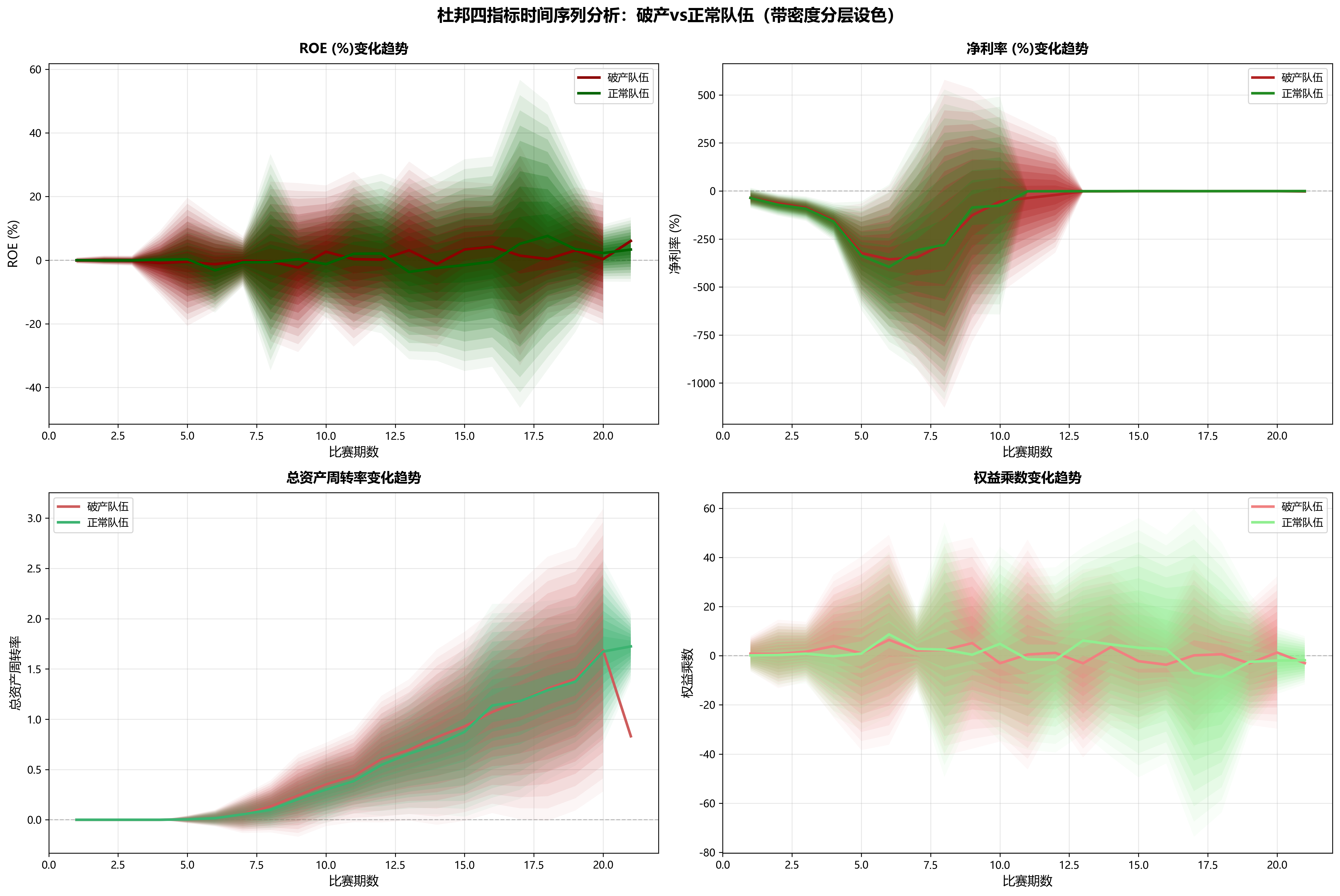
结果 2:ROE 最大化策略在中后期存在风险
| ROE分组 | 队伍数 | ROE范围 | 破产率 | 平均排名 |
|---|---|---|---|---|
| 高ROE组 | 38 | 0.93 ~ 6.69 | 68.4% | 8.2 |
| 中ROE组 | 39 | -0.37 ~ 0.87 | 64.1% | 8.0 |
| 低ROE组 | 38 | -5.63 ~ -0.39 | 63.2% | 6.8 |
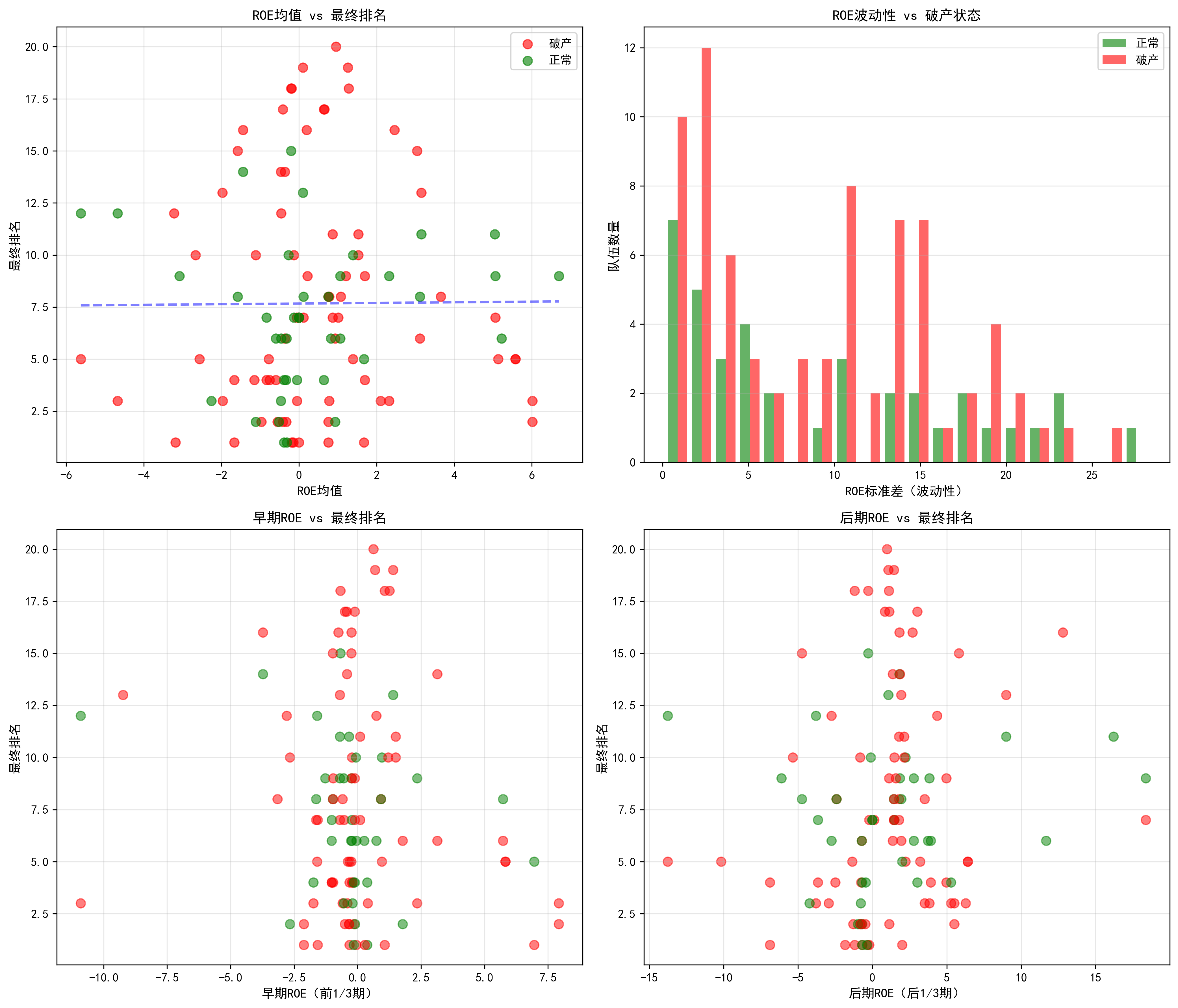
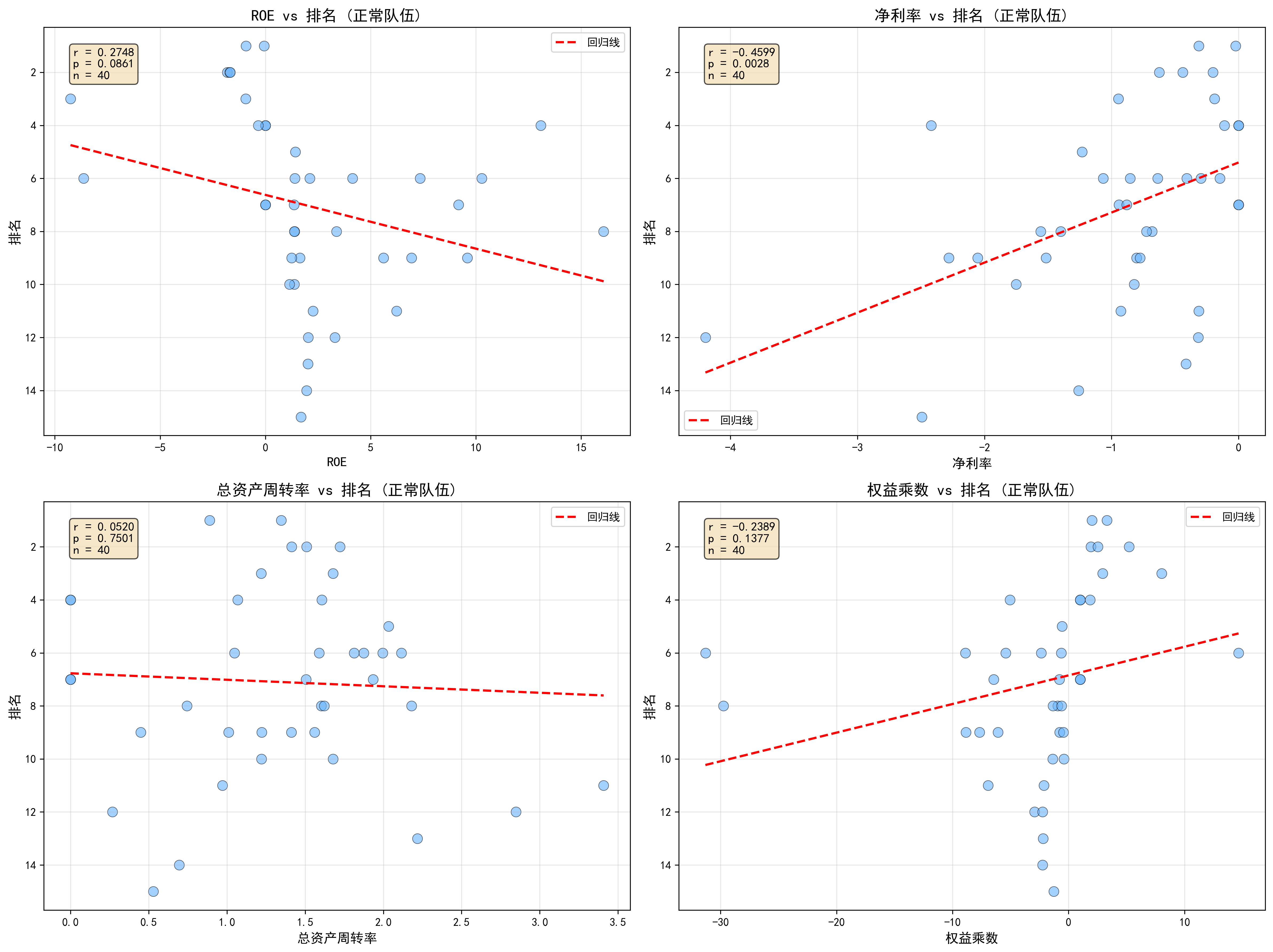
结果 3:局部样本有统计信号,但不足以支持实战策略
| 杜邦指标(40支未破产队伍) | 与排名相关系数 | 显著性 | 解读 |
|---|---|---|---|
| 净利率 | r = -0.460 | p = 0.003 | 仅在该子样本呈统计相关,跨样本可迁移性弱,不能直接用于决策 |
| 权益乘数 | r = -0.239 | p = 0.138 | 趋势存在但不显著 |
| 总资产周转率 | r = 0.052 | p = 0.750 | 与排名几乎无关 |
| ROE | r = 0.275 | p = 0.086 | 仍不构成稳定预测指标 |
结论与研究意义
该验证表明:在 ERP 沙盘场景中,杜邦指标作为排名优化核心几乎不可用。 无论传统算法还是智能算法,只要沿用杜邦逻辑直接驱动策略,都会与百树规则目标发生系统性错位并放大决策风险。 本环节最大的意义是及时止损:明确哪些财务指标不应被继续当作主优化方向。
结论 1:指标边界被明确
ROE 在全样本中无法稳定预测排名,不宜直接作为单目标优化核心指标。
结论 2:分层分析仅用于诊断
破产与未破产队伍分层有助于识别失效原因,但不代表杜邦指标可被直接用于策略优化。
结论 3:局部相关不具实战价值
未破产子样本中的净利率相关难以跨场景泛化,不足以成为可依赖的策略主特征。
结论 4:算法侧应剔除杜邦主驱动
后续建模应把杜邦指标视作失效案例或风险提示,而非核心输入,否则传统/智能算法都可能被误导。
项目反思与退出原因
在项目研讨会议及师生交流、个人思考中,我更关注“能否被企业真正采用”这个落地问题,而不仅是模型在沙盘中的分数表现。 基于研讨会反馈与个人判断,我最终选择退出该方向的持续投入,个人对于科研的认识转向更强调可解释证据链与工程可验证性的研究路径,这也是我对于研究生阶段的期望。
研讨会一线反馈
参会的校友高管(化工、机械制造等行业)普遍对智能体落地持保留态度,核心顾虑不在“模型能不能算”,而在“企业敢不敢用”;在现阶段,尤其是化工产业,AI决策出了问题谁负责,还是依靠人工操作决策(老师傅经验),更加可靠
黑箱可解释性不足
管理决策强调理性、逻辑与事实证据链;当前智能体算法在理论来源、决策来源与责任归因上仍偏黑箱,难以满足管理层审查要求。
实验有效不等于业务可用
即使在沙盘对抗或年报分析预测上取得结果,也不自动等价于企业真实场景采纳,真实企业管理中的复杂变量空间、异常且巨大的扰动会显著抬高落地门槛。
更可能的落地边界
我判断该类产品更适合先用于大学校园内的沙盘比赛:经济风险低、规则约束非常清晰;但是从沙盘对抗智能体的开发成功,到企业智能体的落地应用,中间的过程很极其漫长(首先就是要解决可解释性)。
退出原因与个人转向
我退出该方向,核心原因是“项目叙事过于宏大、证据链不足、可见的期限内落地可信度不够”。这段经历仍让我补足了专业外知识,也更直观看到部分项目存在包装大于落地的问题; 反过来,它强化了我对实打实工程、扎实实验与长期技术打磨的坚持。