省级大创项目 · WaveScan 半导体介电常数微波与智能化检测系统
面向半导体材料介电常数高精度检测的需求,设计并验证了一套基于微波扫频传感的嵌入式智能测量方法,包括射频嵌入式控制、信号采集标定到 TinyML 嵌入式部署的测量系统。以湿度作为介电响应的替代场景完成端到端验证,单次推理约 4.35 ms,RMSE 约 3.1%,MAE 约 2.6%。
摘要
本项目面向半导体材料介电常数高精度检测的需求,设计并验证了一套从微波传感器扫频测量到TinyML模型输出传感结果的完整传感系统。传感器采用基于慢波传输线(SWTL)优化的互补开口环谐振器(CSRR-IDE)平面微波结构,该设计的有效性已被课题组立项前得以验证。为在现有条件下快速验证端到端 pipeline 的可行性,当前的系统设计暂以湿度作为介电响应的替代场景:通过向传感器表面喷洒去离子水模拟湿度梯度,利用RIGOL矢量网络分析仪导出69组S参数样本,并建立谐振频点与湿度的标定关系。
在AI应用的算法层面,针对嵌入式资源受限的特点,设计了一种轻量级一维卷积回归模型(TinyCNN1D),以四通道201频点数组为输入、湿度百分比为输出,经PyTorch训练后通过自行设计的推理引擎部署至STM32H743,初步的基准测试证明该系统设计方式有效。
引言
研究背景与意义
半导体材料的介电常数是制约器件性能与良率的关键参数之一。随着集成电路向小尺度、高集成的方向发展,对介电参数检测的精度与效率提出了愈发严格的要求。基于平面微波传感器的介电常数测量技术,凭借其微型化、非接触、高灵敏度的优势,已成为半导体在线检测领域的重要发展方向。
平面微波传感器的核心机理是微扰法:当待测样品放置于谐振器传感区域时,样品与局部电磁场的相互作用引起谐振频率与谐振深度的可测变化,通过分析S参数频响(包括幅频和相频)即可反演介电常数。然而,S参数与介电常数之间往往呈现复杂的非线性关系,传统的基于单一谐振频点偏移的拟合方法在宽动态范围内精度有限。
与此同时,边缘计算与TinyML(Tiny Machine Learning)的兴起,使得在资源受限的嵌入式设备上运行神经网络模型成为可能;将训练好的模型部署至MCU端,可实现低延迟本地推理,降低对云端通信的依赖,同时也降低高算力设备的购置成本与能耗,特别适用于产线在线监测场景。
本文定位:湿度验证与半导体迁移
需要特别说明的是,本项目的最终目标是半导体材料介电常数的高精度嵌入式检测,而本文所呈现的湿度传感实验是在传感器实物与数据集已就绪的条件下,对"射频控制—信号采集—TinyML建模—MCU部署"这一完整技术范式进行的可行性验证。从物理本质上看,湿度变化对微波频谱的扰动机制(介电常数改变导致谐振特性漂移)与半导体样品完全一致;从工程实现上看,无论是STM32的扫频控制逻辑、ADC采集时序,还是1D-CNN的输入格式(多通道频谱数组)与回归输出(单一物理量),均无需任何结构性修改即可直接迁移。
项目总体架构
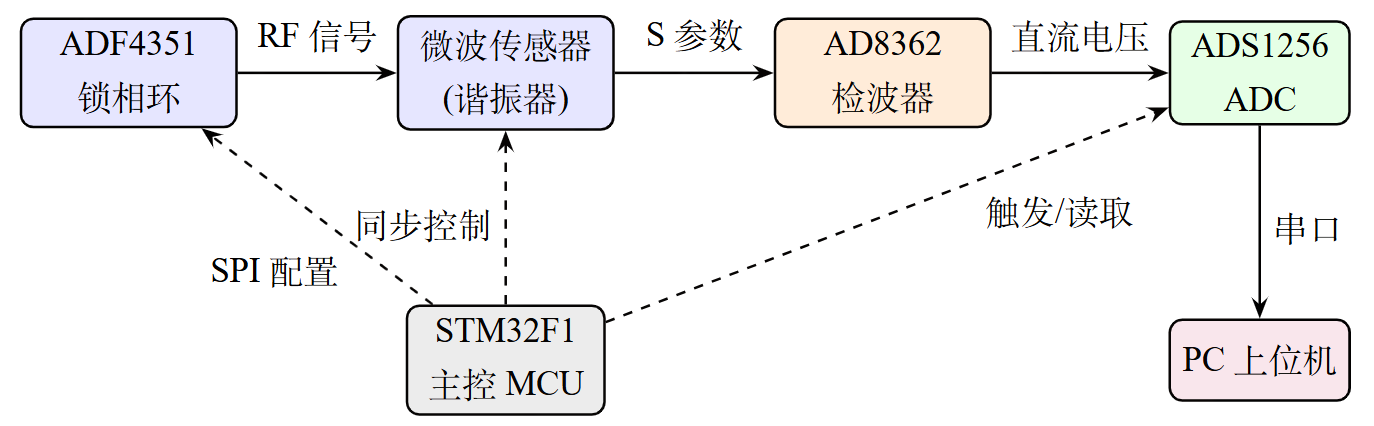
总体技术路线如图1所示,主要包含以下四个核心模块:
- 射频前端硬件:ADF4351锁相环输出1~3.5 GHz可控射频信号,经课题组前期设计的SWTL优化CSRR-IDE平面微波传感器后,由AD8362检波器转换为直流电压,STM32F1完成频点控制与同步ADC采样。
- 数据采集与标定:通过喷雾实验建立湿度梯度,利用RIGOL VNA导出S参数CSV文件,以三次多项式拟合建立谐振点—湿度标定关系。(该标定流程对半导体样品仅需替换为介电常数标定块即可复用)
- TinyML模型设计:基于PyTorch设计1D-CNN回归网络,输入4通道×201频点,输出单一物理量(本系统设计中为湿度百分比);采用全局MinMax归一化、数据增强、剪枝压缩等策略,实现标定。
- STM32嵌入式部署:将模型权重导出为C数组,实现C语言搭建TinyML推理模型(Conv1D、BN+ReLU、GlobalAvgPool、Linear),部署至STM32H743;使用DWT周期计数器精确测量推理耗时。(该推理引擎与输入数据格式对半导体场景完全通用。)

射频扫频系统硬件设计
传感器结构说明
本文所使用的平面微波传感器为课题组前期研究成果,其结构基于互补开口环谐振器(CSRR)并集成交指电容(IDE)以提升灵敏度与Q值,同时采用慢波传输线(SWTL)技术对馈电微带线进行优化,使谐振深度提升约85.5%、Q值提升约65.4%,并实现了功率分配器的小型化。该传感器采用差分测量架构:信号经功分器分为两路,分别送入加载样品的传感支路与参考支路,两路输出经独立检波后做差分运算,可有效抑制射频源功率波动及环境共模噪声(共模抑制比CMRR约46 dB)。
本文的工作并不涉及传感器本体的结构设计与电磁仿真优化,而是聚焦于射频检波系统的嵌入式控制、数据采集以及TinyML模型的部署与验证。传感器的PCB实物由课题组提供,其S参数通过RIGOL矢量网络分析仪导出,作为后续算法建模的数据基础。
系统架构
射频扫频系统主要由三个功能模块组成:可控射频信号源、待测传感器、检波与采集单元。信号源产生步进扫频的微波信号,经传感器后由检波器提取幅度信息,MCU同步控制扫频步进与ADC采样,最终得到频域上的S21传输特性曲线。
| 器件 | 型号 | 关键参数 |
|---|---|---|
| 锁相环 | ADF4351 | 137.5 MHz – 4.4 GHz,分辨率1 Hz,SPI控制 |
| 检波器 | AD8362 | 50 Hz – 3.8 GHz,动态范围>65 dB,线性50 mV/dB |
| ADC | ADS1256 | 24位,最高30 kSPS,SPI接口 |
| 主控MCU | STM32F103 | ARM Cortex-M3,72 MHz,用于锁相环控制 |
ADF4351锁相环信号源
ADF4351是Analog Devices公司推出的宽带频率合成器,集成VCO与整数/小数N分频PLL,输出频率范围为137.5 MHz至4.4 GHz。本系统利用其产生1 MHz至3.5 GHz的扫频信号,步进间隔由软件设定(典型值为10~20 MHz)。
STM32F1通过三线SPI接口配置ADF4351的六个32位寄存器,设定参考频率、反馈分频比、VCO频段等参数。VCO输出经低通滤波器后得到纯净的正弦波信号,输入至待测传感器。
AD8362真有效值检波器
AD8362是一款真有效值(True RMS)响应功率检波器,可在50 Hz至3.8 GHz范围内提供65 dB以上的动态范围。其内部采用对数放大器架构,输出电压与输入信号功率呈线性关系(斜率约50 mV/dB),能够准确测量各种调制波形的平均功率。
在本系统中,AD8362被配置为单端输入模式,传感器输出信号经耦合电容接入INHI引脚。输出端VOUT直接连接至VSET形成测量模式闭环,输出电压范围为0.5~3.5 V,可直接被后级ADC采样。为提高精度,检波器前端增加了阻抗匹配网络与低噪声放大器,以提升信噪比。
STM32F1扫频控制与同步采集
STM32F1作为系统主控,承担以下任务:通过SPI配置ADF4351,依次设置扫频序列中的每个频点;在每个频点稳定后(约2~5 ms锁相建立时间),触发ADS1256进行ADC转换;读取24位ADC结果,通过串口上传至PC端进行存储与处理。
扫频过程中,STM32F1以固定步进(如17.5 MHz)遍历1 MHz至3.5 GHz,共采集201个频点的幅度数据。单次完整扫频耗时约0.5~1秒,满足静态湿度测量的时间分辨率需求。
传感器标定与数据基础
湿度梯度实验设计
为建立S参数与湿度的对应关系,实验采用喷雾法构建湿度梯度。具体步骤如下:将待测传感器(基于PCB微带线的微波谐振器)置于恒温恒湿环境中;使用喷雾瓶向传感器表面喷洒去离子水,每次喷雾记为1个单位;分别记录0、10、20、30、40、50、60、70、80、85、90、95、100、105、110、120、130、140、150、160、170、180、190次喷雾后的S参数;每个喷雾剂量重复测量3次,共获得69组数据。
实验结束后,使用RIGOL矢量网络分析仪(VNA)导出每个状态的S参数CSV文件,文件格式包含频率、S21幅度(dB)、S21相位(°)、S11幅度(dB)、S11相位(°)五列。
谐振点—湿度标定关系
四维度原始数据可视化
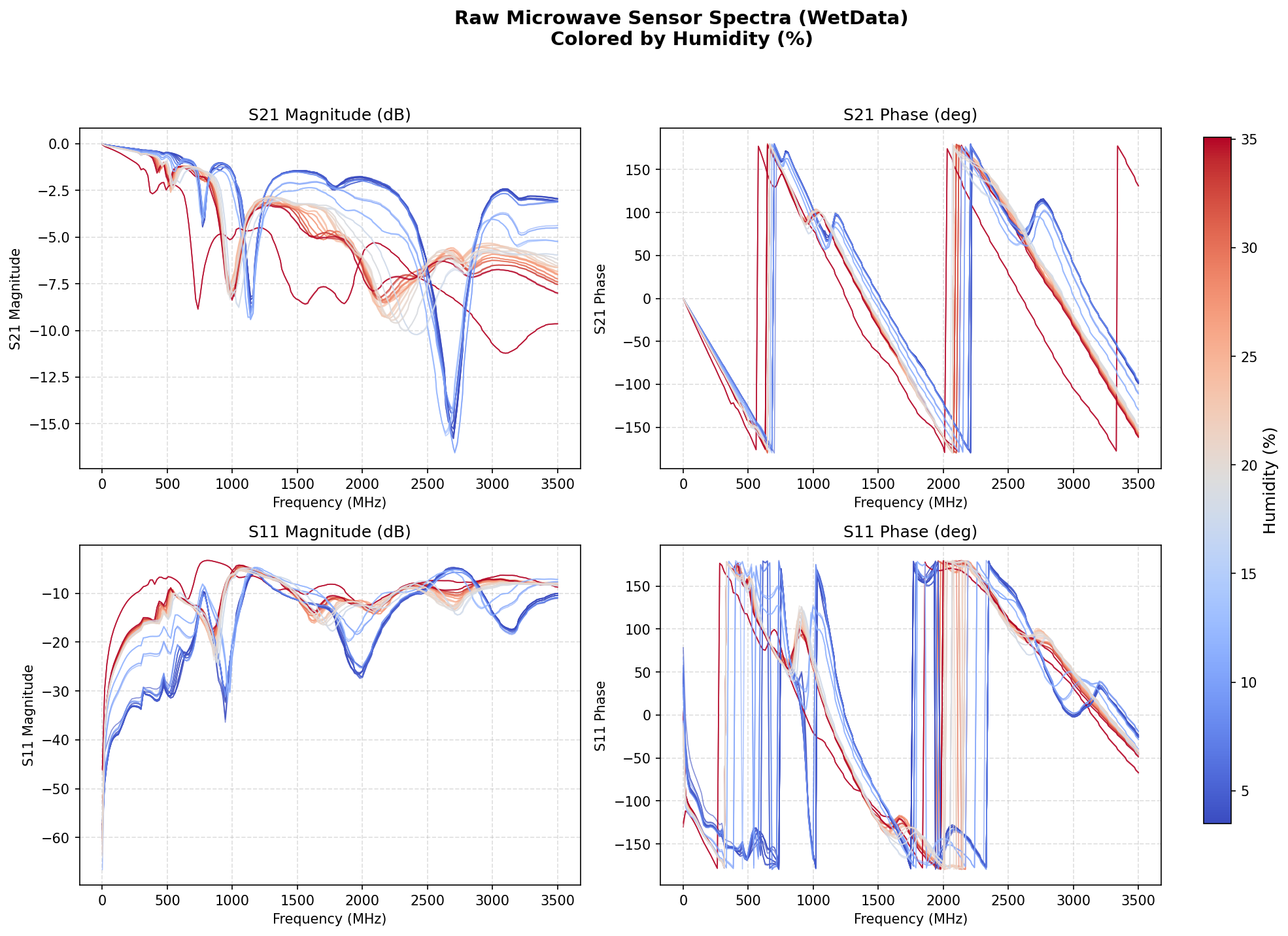
为直观展示不同湿度条件下微波频谱的变化规律,图3给出了全部69组样本的四通道原始数据(S21幅度、S21相位、S11幅度、S11相位),曲线按湿度百分比着色。可以观察到,随着湿度增加(蓝色→红色),S21幅度在2.5~3.0 GHz区间的谐振谷点发生明显偏移与展宽,同时S11反射特性的相位跳变位置也呈现系统性漂移,这些频域特征构成了模型学习湿度映射的关键依据。
数据集构建
最终构建的数据集包含69个样本,每个样本为$4 \times 201$的浮点数组:
- 通道0:S21幅度(dB)
- 通道1:S21相位(°)
- 通道2:S11幅度(dB)
- 通道3:S11相位(°)
湿度标签通过reference.csv映射表获得,范围为3.5%至35.1%。数据预处理采用全局MinMax归一化:将所有样本、所有通道的804个数据点拉平后统一缩放至$[0,1]$区间,以保证不同通道、不同样本之间的量纲一致性。
TinyML模型设计与训练
模型架构:TinyCNN1D
针对嵌入式MCU的内存与算力限制,本项目设计了一种轻量级一维卷积神经网络TinyCNN1D,其架构如表所示。模型输入为$(4, 201)$的张量,输出为单一浮点数(湿度百分比)。
| 层 | 配置 | 输出尺寸 |
|---|---|---|
| 输入层 | 4通道×201频点 | $(4, 201)$ |
| MultiScaleBlock (stem) | 分支核$[3,5,7]$,stride=2,out=8 | $(8, 101)$ |
| BatchNorm + ReLU | — | $(8, 101)$ |
| Conv1D | $8\to16$,$k=5$,$s=2$,$p=2$ | $(16, 51)$ |
| BatchNorm + ReLU | — | $(16, 51)$ |
| Conv1D | $16\to16$,$k=3$,$s=2$,$p=1$ | $(16, 26)$ |
| BatchNorm + ReLU | — | $(16, 26)$ |
| AdaptiveAvgPool1D | output=1 | $(16, 1)$ |
| Flatten | — | $(16)$ |
| FC + ReLU | $16\to16$ | $(16)$ |
| Dropout(0.1) | — | $(16)$ |
| FC + ReLU | $16\to8$ | $(8)$ |
| Dropout(0.1) | — | $(8)$ |
| FC | $8\to1$ | $(1)$ |
模型的核心创新在于首层的多尺度卷积块(MultiScaleBlock)。传统单核卷积难以同时捕捉微波频谱中的宽频谐振趋势与窄频纹波细节。MultiScaleBlock并行使用3、5、7三种核尺寸的卷积分支,将感受野覆盖从局部细节到中等范围模式,分支输出按通道拼接后统一进行BatchNorm与ReLU激活。仅在首层使用多尺度(stem模式),后续层采用标准卷积,以控制参数量与计算复杂度。
模型总参数量约8,000个,权重文件(FP32 ONNX)仅14.8 KB,极适合MCU部署。
训练策略
训练在PyTorch框架下进行,关键超参数如下:优化器为Adam,学习率0.001,权重衰减$10^{-5}$;损失函数为均方误差(MSELoss);学习率调度为ReduceLROnPlateau,因子0.5,耐心10轮;早停耐心50轮,基于验证集RMSE;批量大小8;最大epoch 300。
由于数据集仅69个样本,属于典型的"小样本"场景,为防止过拟合,采用了以下数据增强策略:高斯噪声(标准差0.005)、循环频移(最大偏移3个频点)、幅度缩放($[0.95, 1.05]$范围内随机缩放)、频率拉伸($[0.98, 1.02]$范围内线性插值拉伸/压缩后裁剪回201点)、Mixup(30%概率与另一随机样本按Beta(0.2, 0.2)混合)。
此外,训练结束后对模型进行了幅度剪枝(Magnitude Pruning,剪枝比例30%),随后进行100轮微调恢复精度,以进一步压缩模型体积。
与传统方法的对比
为评估深度学习模型在本任务上的必要性,本文同步测试了五种传统回归方法作为基线对比。以下逐一给出各方法的数学模型与实验设置。
(1)三次多项式拟合:从S21幅度曲线中提取谐振谷点频率$f_{res}$(单位Hz),建立湿度与谐振频率的三次多项式关系,拟合得到具体系数如下:
$$H = 6.20\times10^{-26} \cdot f_{res}^3 - 3.81\times10^{-16} \cdot f_{res}^2 + 7.12\times10^{-7} \cdot f_{res} - 357.56$$
其中常数项$-357.56$反映了基线偏移,一次项系数$7.12\times10^{-7}$表征了谐振频率对湿度的主导线性灵敏度,而高次项系数极小($10^{-16}$量级),说明在本实验的湿度范围内,频移的非线性偏离相对微弱。该方法的物理意义明确:传感器谐振频率随湿度单调漂移,多项式可捕捉其非线性趋势。
(2)线性回归:将$4 \times 201$频谱展平为804维向量$\mathbf{x} \in \mathbb{R}^{804}$,建立线性映射$\hat{H} = \mathbf{w}^{\mathsf{T}} \mathbf{x} + b$。权重$\mathbf{w}$与偏置$b$通过最小化均方误差求解:$\min_{\mathbf{w},b} \sum_{i}(H_i - \hat{H}_i)^2$。
(3)岭回归:在线性模型基础上施加$L_2$正则化($\alpha=1.0$),目标函数为$\min_{\mathbf{w},b} \sum_{i}(H_i - \hat{H}_i)^2 + \alpha \|\mathbf{w}\|_2^2$。正则化项抑制权重大幅波动,降低过拟合风险。
(4)支持向量回归(SVR):采用RBF核函数$K(\mathbf{x}_i, \mathbf{x}_j) = \exp(-\gamma \|\mathbf{x}_i - \mathbf{x}_j\|^2)$,参数$C=10.0$,通过$\varepsilon$-不敏感损失在特征空间中寻找最优超平面。
(5)随机森林:构建200棵决策树,每棵树在随机子集上训练,最终预测取平均:$\hat{H} = \frac{1}{T}\sum_{t=1}^{T} h_t(\mathbf{x})$,最大深度10。
传统ML方法采用5折交叉验证获取无偏预测,结果汇总于表。需要特别指出的是,线性回归的$R^2$高达0.998、MAE仅0.18%,岭回归与随机森林也表现出极低误差。该现象需结合数据维度与样本规模审慎解读:
- 高维小样本过拟合:展平后的输入维度为804,远超69个样本数量。线性回归仅805个参数(804维权重+1个偏置),在特征数远大于样本数的欠定系统下,5折交叉验证仍可能给出过于乐观的估计——训练折(约55样本)可轻易找到近乎完美的拟合超平面,而验证折(约14样本)因与训练集高度同分布也呈现极低误差。
- 特征高度相关:频谱数据在相邻频点间具有强连续性,804维特征并非独立,线性模型可利用这种相关性在统计上获得较好的拟合表现,但本质上缺乏对频谱局部谐振结构的显式物理建模。
- 部署不可行:线性回归虽仅805个参数,但需存储全部804维浮点权重(约3.2 KB)并在推理时执行804次乘加;随机森林200棵树的模型体积达数MB,远超STM32H743的2 MB Flash预算,且决策树的条件分支逻辑在MCU上执行效率极低。
客观数学分析:高维小样本下的解稳定性
上述现象并非主观臆测,可通过矩阵分析与统计实验加以客观量化。
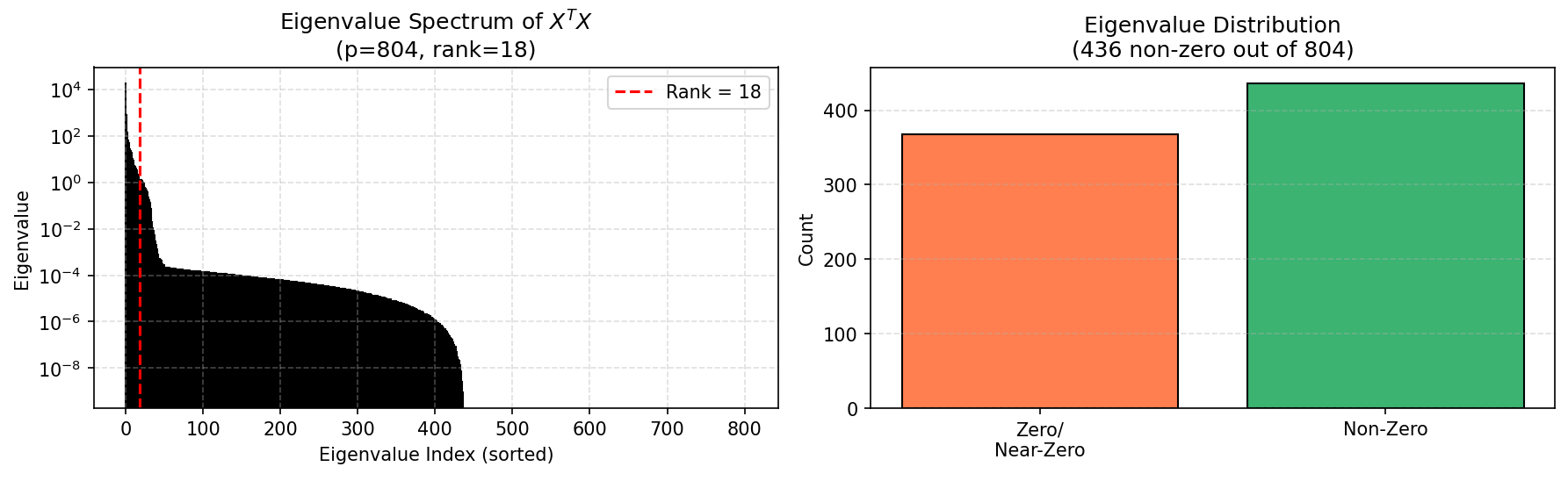
(1)$X^{\mathsf{T}}X$的秩与条件数
将69组样本的$4\times201$频谱展平为设计矩阵$X\in\mathbb{R}^{69\times804}$,计算$X^{\mathsf{T}}X$的秩与条件数:$\mathrm{rank}(X^{\mathsf{T}}X) = 18$,而理论上最大不超过$\min(n,p)=69$。这意味着804维特征空间中仅有18个独立方向携带有效信息,其余$804-18=786$维几乎完全共线;条件数$\kappa(X^{\mathsf{T}}X) = 2.19\times10^{13}$,远超数值稳定阈值$10^6$。$X^{\mathsf{T}}X$已严重病态乃至接近奇异,其伪逆解对输入扰动极度敏感——频谱中0.01%的噪声即可导致预测发生量级为$10^6$%的漂移。
图6展示了$X^{\mathsf{T}}X$的特征值谱:仅前18个特征值显著非零,其余均衰减至机器精度附近。这正是"先射箭再画靶"的数学本质——线性回归在18维有效子空间上拟合了信号,却在786维零空间上任意游走,只要训练集分布不发生剧烈变化,交叉验证便无法暴露这种不稳定性。
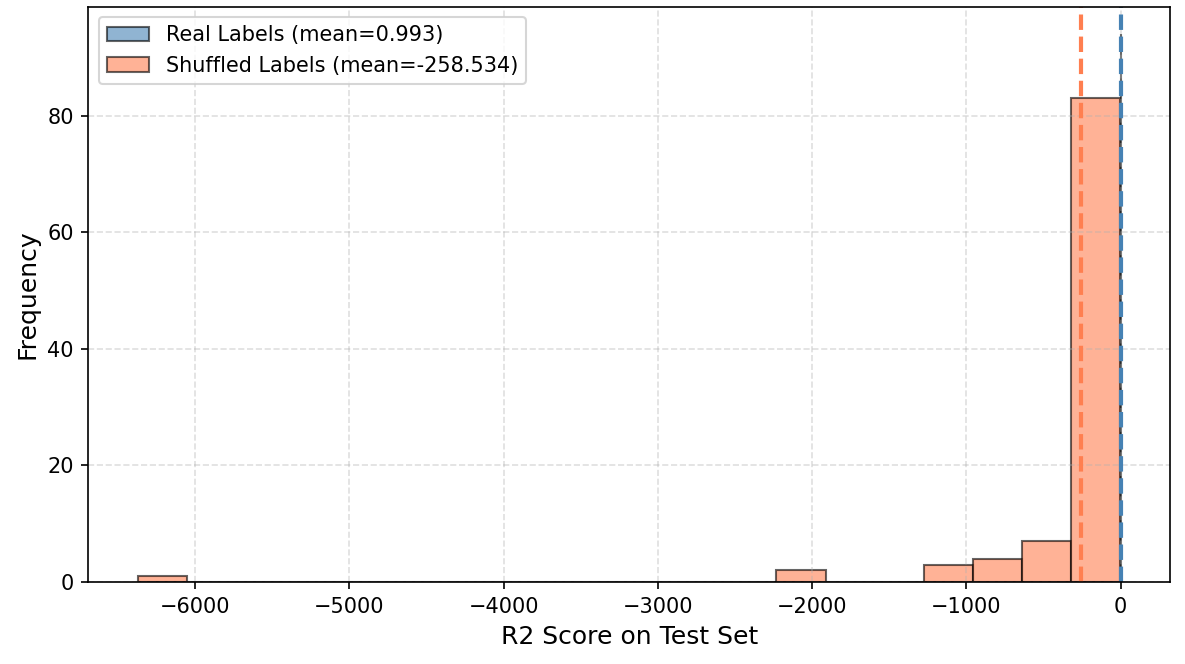
(2)置换检验(Permutation Test)
为检验高$R^2$是否源于对真实信号的提取而非对噪声的过拟合,进行100次标签置换实验:将湿度标签随机打乱后重新训练线性回归,重复100次随机80/20划分。结果显示:真实标签测试集$R^2 = 0.993 \pm 0.027$;置换标签测试集$R^2 = -258.5 \pm 719.8$(剧烈震荡,完全失效)。置换检验证明线性回归确实捕捉到了湿度—频谱之间的真实物理关联,而非纯粹拟合噪声。然而,这并不能否定"解的不唯一性"问题——在欠定系统下,存在无穷多组权重都能同样好地拟合真实信号,其中任何一组都可能在传感器老化、温度漂移或批次差异导致的新数据分布上失效。
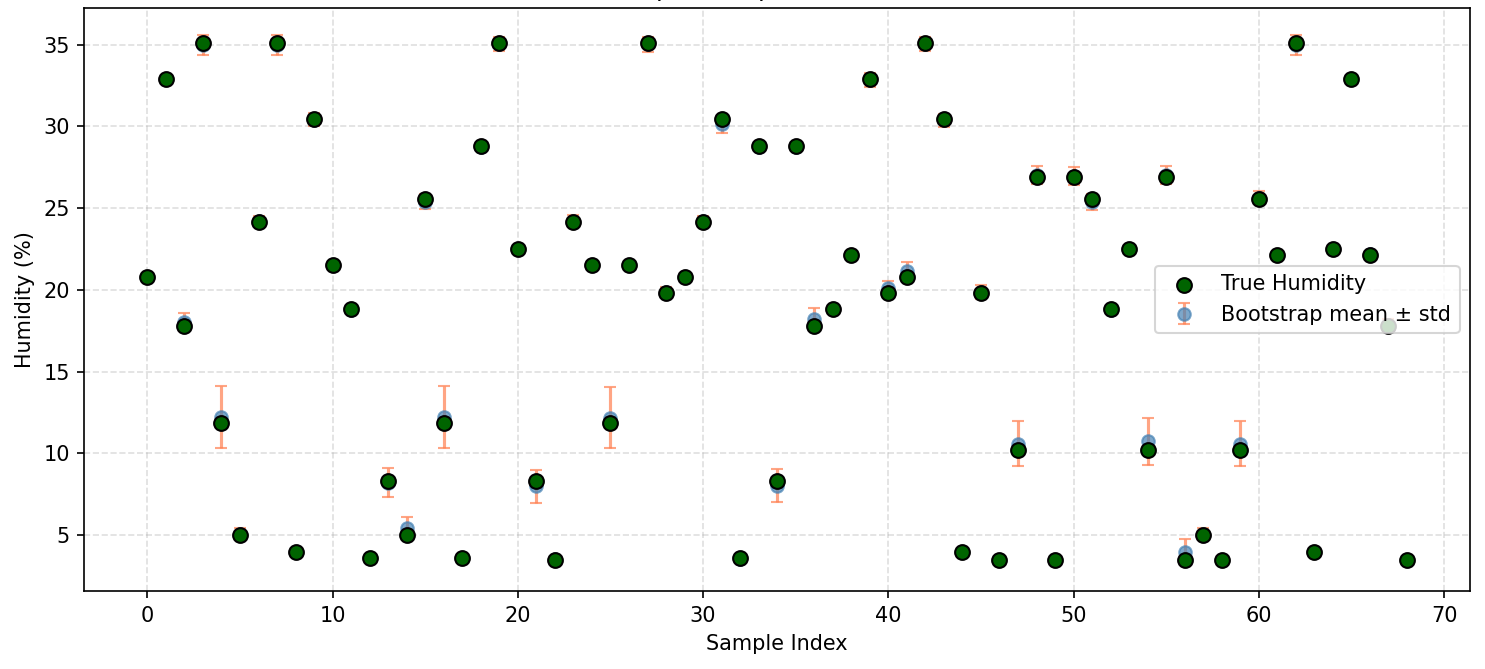
(3)Bootstrap预测方差
对69个样本进行200次Bootstrap重采样(有放回抽样),每次训练线性回归并在全部样本上预测,统计预测值的标准差:平均标准差0.47%,最大标准差1.88%。图8显示,部分样本的预测值在Bootstrap重采样下波动接近$\pm2$%,表明即使训练集仅发生微小变化,线性回归的预测也可能出现可感知的漂移。
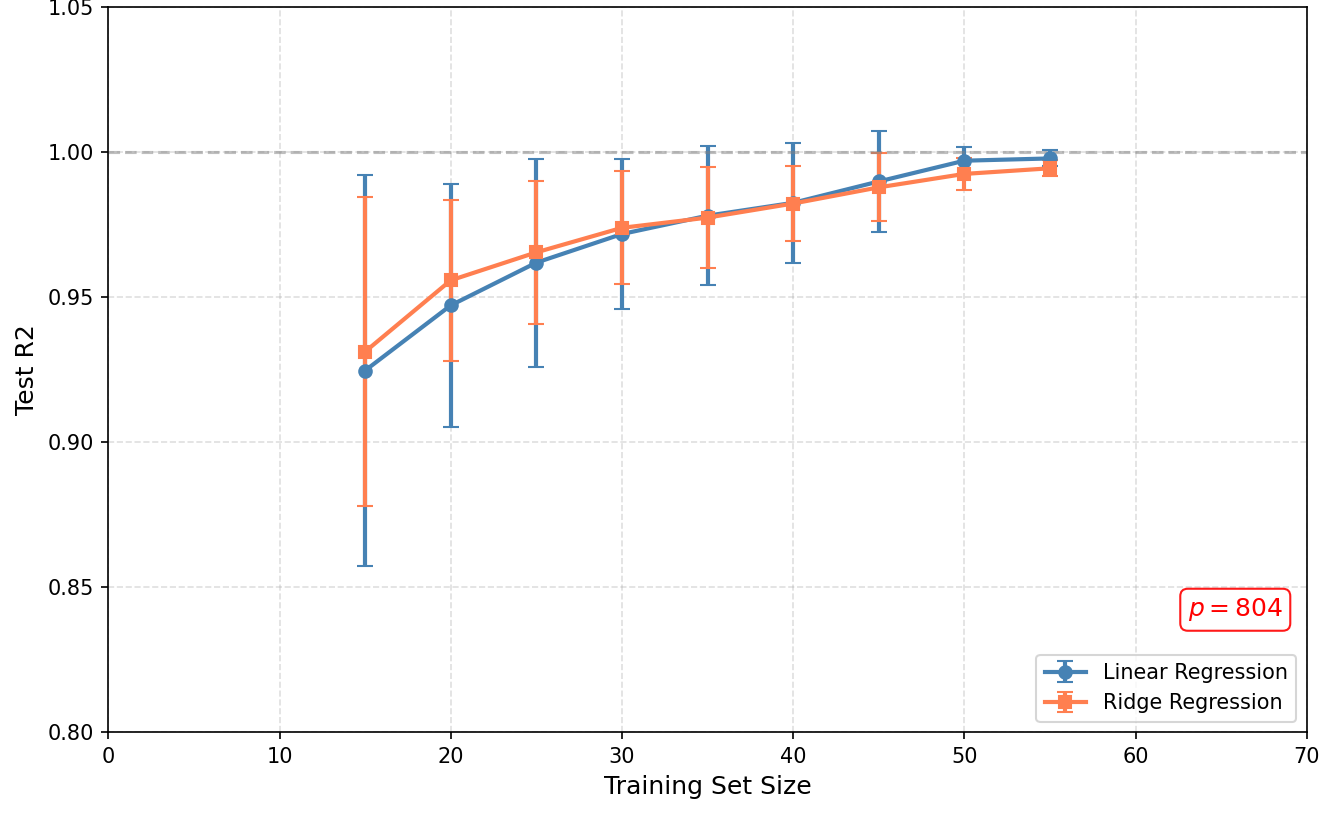
(4)学习曲线:样本量增长能否挽救线性回归?
图9展示了不同训练集规模下线性回归与岭回归的测试$R^2$(30次随机试验取均值)。结果显示:即使训练样本从15增至55,线性回归的$R^2$始终维持在0.92以上,且随样本量增加几乎没有下降迹象。这说明问题的核心不在于"样本太少",而在于"特征维度相对样本数永远过高"——只要$p > n$,系统便持续处于欠定状态,交叉验证无法有效惩罚模型复杂度。
长期有效性讨论:线性回归 vs. TinyCNN1D
综合上述分析,可对两种方法的长期有效性作出如下判断:
线性回归的局限——尽管当前$R^2$高达0.998,但其可靠性建立在三个脆弱前提之上:训练集与测试集严格同分布、频谱无系统性偏移、传感器特性不变。一旦实际部署中遇到温度变化导致谐振频率整体平移、传感器老化引起$Q$值衰减、或不同批次PCB的介电常数差异,804维独立权重将使预测发生不可控漂移。此外,线性回归无法利用频谱的局部连续性先验,其"全局加权"策略对频域细节(如谐振谷的宽度与深度变化)缺乏物理可解释性。
TinyCNN1D的优势——卷积神经网络通过以下机制保障了长期鲁棒性:局部感知,卷积核仅覆盖3~7个频点,对频谱的绝对平移不敏感(谐振谷左移或右移不影响其局部形状);权重共享,同一卷积核在整个频带上滑动,参数量严格受控(约8,000个),且远小于有效特征维度;结构正则化,BatchNorm、Dropout、数据增强等多重手段共同约束了解空间,使模型在面对分布偏移时比高维线性模型更具稳定性。从数学上看,CNN的卷积结构将解空间从$\mathbb{R}^{804}$的全局加权压缩至卷积核参数的有界子空间,本质上是一种与频谱物理特性相匹配的强先验。
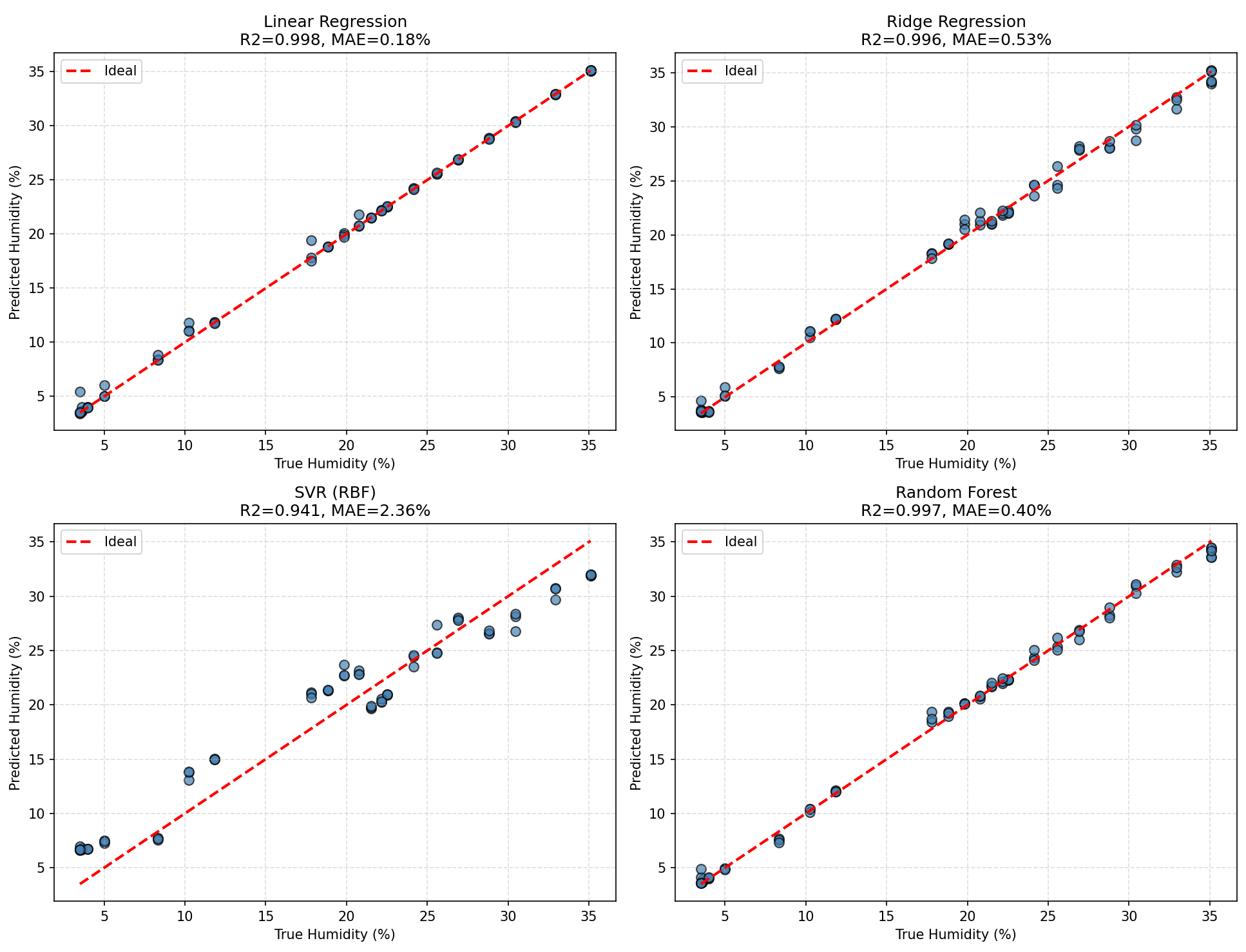
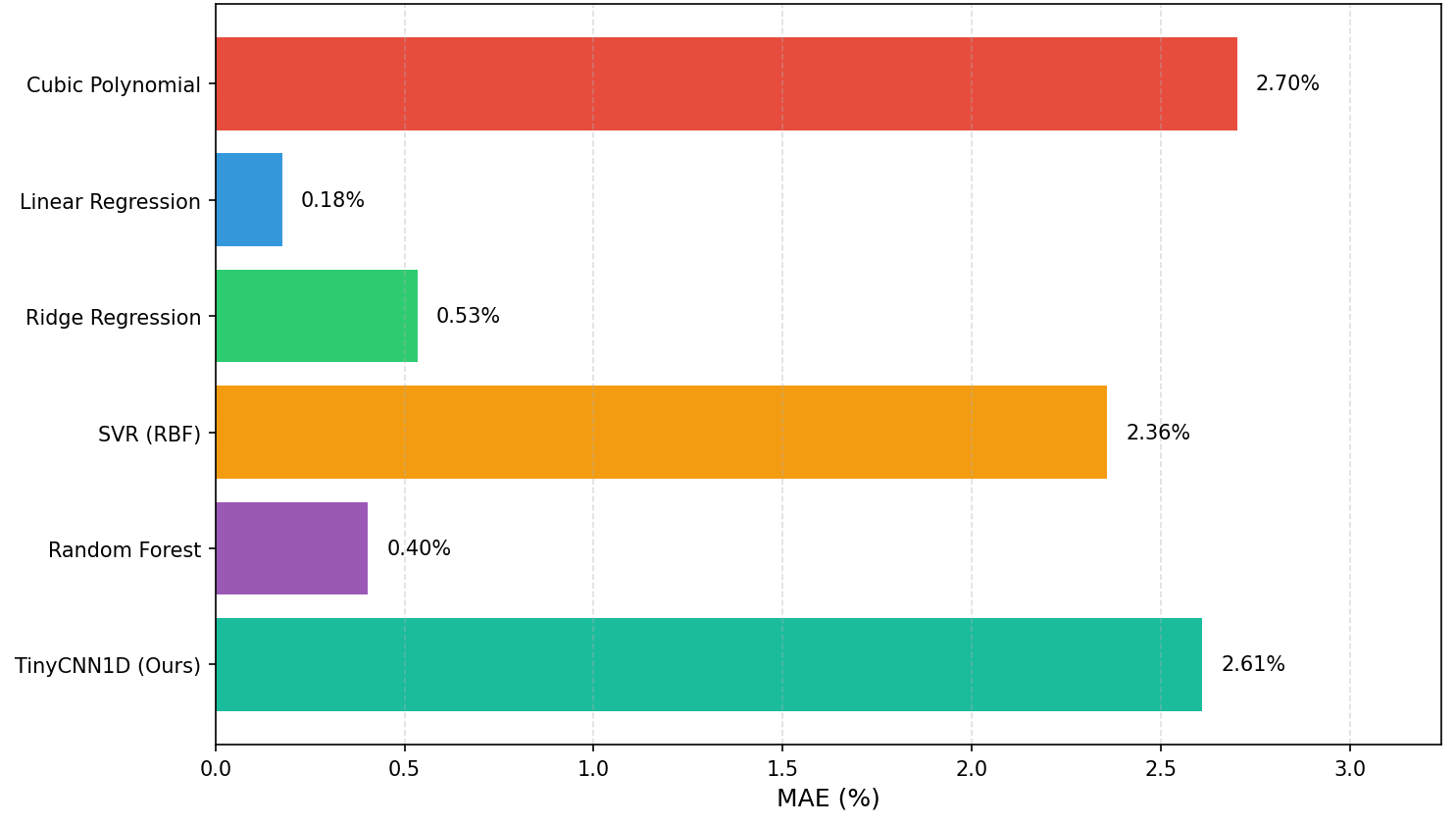
| 方法 | MSE | RMSE (%) | MAE (%) | R² |
|---|---|---|---|---|
| 三次多项式拟合 | 9.29 | 3.05 | 2.70 | 0.914 |
| 线性回归 | 0.19 | 0.44 | 0.18 | 0.998 |
| 岭回归 | 0.45 | 0.67 | 0.53 | 0.996 |
| SVR (RBF) | 6.40 | 2.53 | 2.36 | 0.941 |
| 随机森林 | 0.31 | 0.56 | 0.40 | 0.997 |
| TinyCNN1D (本文) | 9.65 | 3.11 | 2.61 | 0.900 |
相比之下,TinyCNN1D的优势体现在三个方面:结构化特征提取——多尺度卷积显式捕捉频谱的局部谐振模式,而非简单依赖全连接映射;部署可行性——约8,000参数、14.8 KB的模型体积可完全嵌入MCU Flash;泛化鲁棒性——训练过程中采用数据增强、Dropout、早停等多重正则化手段,使其在面对训练集分布偏移时比高维线性模型更具稳定性。
训练结果
模型经过5折交叉验证与最终全量训练,收敛情况良好。图12展示了训练过程中的损失曲线与验证指标演化。总损失在前20个epoch内迅速下降并趋于稳定;验证$R^2$在约20轮后达到0.85以上并最终稳定在0.90附近;验证RMSE与MAE分别收敛至约0.12和0.10(归一化尺度),对应真实湿度误差约3~4个百分点。训练过程中验证集RMSE最低达到约2.5%,表明模型具备较好的泛化能力。全量训练后导出ONNX格式模型,作为后续嵌入式部署的中间表示。
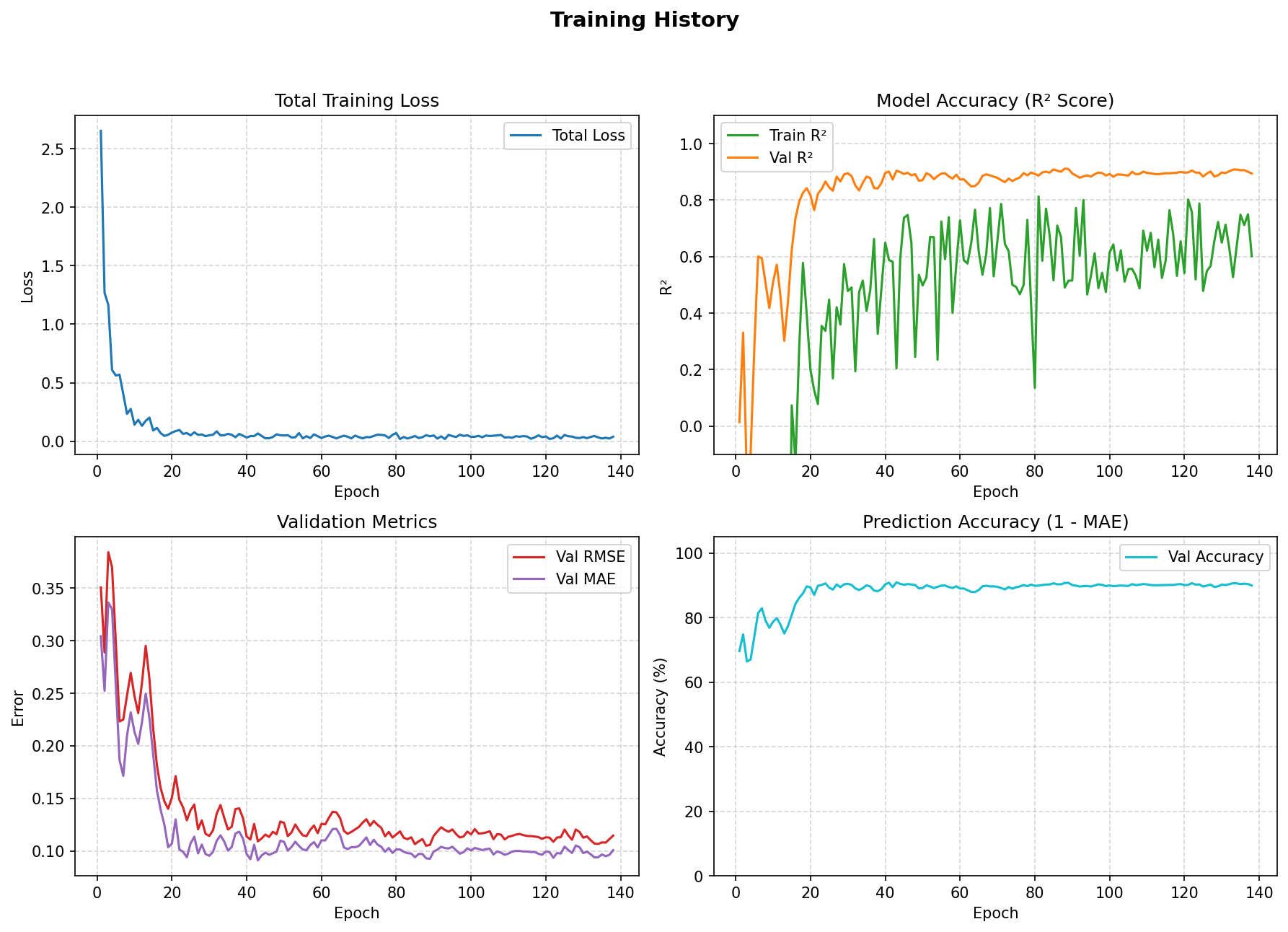
STM32H743嵌入式部署
部署方案选择
STM32H743是一款基于ARM Cortex-M7内核的高性能MCU,主频480 MHz,集成双精度FPU与DSP指令集,配备2 MB Flash与1 MB RAM。虽然STM32CubeMX提供了X-CUBE-AI中间件用于自动模型转换,但本项目选择手动搭建C语言推理引擎,原因如下:模型结构简单(仅3层卷积+2层FC),手写实现工作量可控;避免对CubeMX生成代码的依赖,保持工程的可移植性与可维护性;直接控制内存布局与计算流程,便于精确优化与调试。
权重导出与C数组生成
部署流程如图13所示。首先,通过Python脚本加载PyTorch模型状态字典,将各层的权重(Conv1D核、BatchNorm的$\gamma$/$\beta$/running_mean/running_var、FC的$W$/$b$)逐层导出为C语言const float数组。BatchNorm参数在导出时预计算为缩放因子与偏移量:
$$\text{scale} = \frac{\gamma}{\sqrt{\sigma^2 + \epsilon}}, \quad \text{bias}_{new} = \beta - \mu \cdot \text{scale}$$
这样在推理阶段只需执行一次乘加运算即可同时完成归一化与ReLU激活。
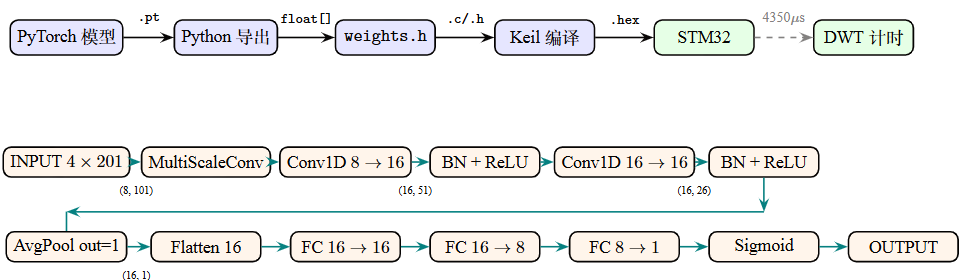
纯C推理引擎实现
STM32H743内的嵌入式TinyML推理模型实现了以下核心算子:
(1)一维卷积(Conv1D):采用直接卷积实现,支持任意stride与padding。对于输入$X \in \mathbb{R}^{C_{in} \times L_{in}}$、权重$W \in \mathbb{R}^{C_{out} \times C_{in} \times K}$,输出$Y \in \mathbb{R}^{C_{out} \times L_{out}}$的计算公式为:
$$Y[o, l] = \sum_{c=0}^{C_{in}-1} \sum_{k=0}^{K-1} W[o, c, k] \cdot X\left[c, l \cdot s + k - p\right]$$
其中边界外的索引视为0(zero-padding)。
(2)BatchNorm + ReLU:利用预计算的scale与bias_new,对每通道每位置执行$Y = \max(0, X \cdot \text{scale} + \text{bias}_{new})$。
(3)AdaptiveAvgPool1D:将每个通道的所有时域点取平均,输出尺寸恒为$(C, 1)$。
(4)全连接层(Linear):标准矩阵向量乘法加偏置:$y = Wx + b$。
为避免栈溢出,所有大于1 KB的中间特征图均采用static关键字分配在全局数据区(.bss段),而非函数栈上。推理过程不涉及动态内存分配,完全符合嵌入式系统的确定性要求。
输入数据与反归一化
输入的CSV数据在PC端通过训练时的全局MinMaxScaler进行归一化,归一化后的$[0,1]$浮点数组直接硬编码为C的static const float INPUT_DATA。MCU端推理输出的是归一化湿度值,需通过反归一化得到真实湿度百分比:
$$H_{real} = H_{norm} \cdot (H_{max} - H_{min}) + H_{min}$$
其中$H_{min}=3.5\%$,$H_{max}=35.1\%$,由训练集标签范围确定。
测试结果与分析
测试平台与配置
测试基于STM32H743IIT6核心板,系统时钟配置为480 MHz(PLL输出),启用Cortex-M7的D-Cache与I-Cache。串口USART1配置为115200波特率,用于printf调试输出。
为精确测量推理耗时,采用ARM Cortex-M内置的DWT周期计数器(Data Watchpoint and Trace Cycle Counter)。该计数器以CPU主频直接计数,分辨率为$1/480 \approx 2.08$ ns,远优于毫秒级的SysTick。测试前在main()中使能DWT:
CoreDebug->DEMCR |= CoreDebug_DEMCR_TRCENA_Msk;
DWT->CTRL |= DWT_CTRL_CYCCNTENA_Msk;全量基准测试结果
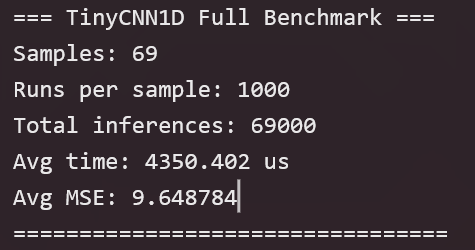
将69个样本全部嵌入Flash,每个样本连续推理1000次,共计69,000次推理。测试输出如下表所示。
| 指标 | 结果 |
|---|---|
| 样本总数 | 69 |
| 每样本推理次数 | 1000 |
| 总推理次数 | 69,000 |
| 单次推理平均耗时 | 4350.4 μs(约4.35 ms) |
| 平均MSE | 9.6488 |
| RMSE | 3.11 % |
| MAE | 2.61 % |
| 最大绝对误差 | 6.45 % |
结果分析
(1)推理速度:单次推理耗时约4.35 ms,对应约208万CPU时钟周期($4.35 \times 10^{-3} \times 480 \times 10^6 \approx 2.09 \times 10^6$)。对于需要秒级更新率的湿度监测应用,该速度完全满足实时性要求。若需进一步提升,可考虑:启用D-Cache预取、将权重放至DTCM(零等待RAM)、或使用CMSIS-NN优化卷积内核。
(2)精度分析:RMSE约3.1%,MAE约2.6%,意味着预测湿度与真实湿度平均偏差在2~3个百分点。以典型湿度20%为例,预测值落在17%~23%区间。最大误差6.45%出现在部分极端湿度条件下,可能与训练样本在这些区域的稀疏性有关。
(3)误差来源:
- 模型容量:TinyCNN1D仅约8K参数,模型表达能力有限;
- 数据量:69个样本对于深度学习而言仍属小样本,虽然采用了数据增强,但难以覆盖全部工况;
- 标定误差:reference.csv中的湿度值基于三次多项式拟合间接获得,本身存在拟合误差;
- 量化误差:部署使用FP32权重,未进行INT8量化,因此不存在量化精度损失,但纯C实现的浮点运算顺序与PyTorch存在微小差异(累加顺序不同导致的舍入误差),验证表明该差异小于$10^{-6}$,可忽略。
结论与展望
工作总结
本项目面向半导体材料介电常数检测的最终目标,以湿度为替代场景,完成了一套从射频硬件到TinyML部署的完整嵌入式智能微波测量范式验证,主要贡献包括:
- 技术范式固化:验证了"ADF4351锁相环扫频 + AD8362检波 + STM32同步采集 + 1D-CNN回归 + MCU本地推理"的全链路可行性,该范式对半导体介电常数检测可直接复用,仅需替换标定样品与标签映射;
- 数据集与标定:通过喷雾实验建立69组标定数据,以三次多项式拟合验证了谐振点—湿度关系的非线性单调性,积累了从S参数CSV到归一化训练集的完整数据工程经验;
- TinyML模型设计:针对小样本、低算力场景设计了TinyCNN1D模型,采用多尺度卷积与数据增强策略,经5折交叉验证与全量训练后导出ONNX;
- 嵌入式部署:将模型以C语言推理引擎形式部署至STM32H743,无需X-CUBE-AI等中间件,单次推理约4.35 ms,69样本平均RMSE约3.1%,验证了在480 MHz Cortex-M7上运行千参数级CNN进行频谱回归的技术可行性。
未来工作
- 半导体样品迁移:将待测对象由湿土壤替换为已知介电常数的标准半导体标定块,重新建立"介电常数—S参数"标定数据集,完成从湿度验证到目标场景的技术迁移;
- 在线推理:当前部署为"封闭推理"(数据硬编码在Flash中),下一步将集成实时ADC采集,使传感器差分输出直接送入模型进行在线介电常数预测;
- 多物理量融合:除S参数外,引入温度、气压等环境参数作为额外输入通道,补偿温度对介电常数测量的交叉敏感性,提升模型鲁棒性;
- 量化与加速:尝试INT8量化与CMSIS-NN优化,目标将推理耗时降至1 ms以内(当前4ms),以满足产线高速巡检需求;
- 产线集成:将射频检波板、传感器与MCU模块集成至标准化探针台或晶圆检测工位,构建面向半导体制造的可嵌入式在线检测节点。
参考文献
- H. Wu and G. Liu, "A Differential Measurement System for Liquid Dielectric Constant Optimized by SWTL," IEEE Sensors J., vol. 25, no. 13, pp. 1–10, Jul. 2025, doi: 10.1109/JSEN.2025.3577695.
- Analog Devices. ADF4351 Datasheet: Wideband Synthesizer with Integrated VCO, 2010.
- Analog Devices. AD8362 Datasheet: 50 Hz to 3.8 GHz 65 dB TruPwr Detector, 2015.
- A. Paszke et al. "PyTorch: An Imperative Style, High-Performance Deep Learning Library." NeurIPS, 2019.
- P. Warden and D. Situnayake. TinyML: Machine Learning with TensorFlow Lite on Arduino and Ultra-Low-Power Microcontrollers. O'Reilly Media, 2019.
- STMicroelectronics. STM32H743 Reference Manual (RM0433), 2021.