
Linux边缘运算设备与边缘侧神经网络的应用实践
项目面向垃圾分类工程装置,基于 NVIDIA Jetson Nano B01 完成边缘侧视觉识别系统搭建。 在固定机位与装置内采样条件下,完成 1474 张样本的数据采集与清洗,并通过 MobileNetV2 两阶段迁移学习完成模型训练与部署验证。 系统采用“训练端与推理端分离”的分布式工程路径:训练在高性能环境完成,推理在 Jetson 端实时执行并输出 HDMI 分类结果。
摘要
本项目以“边缘设备可部署、未知样本可泛化”为目标,设计并实现了一个垃圾分类装置(比赛限制 40cm × 40cm × 60cm 以下)。 工程围绕视觉识别主链路展开:数据采集与清洗、ROI 规范化、模型训练、Jetson 端部署、HDMI 结果输出。 在比赛现场未知样本测试中,系统实现 7/8 的识别成功率,验证了模型在受控工程场景下的实用性。
系统架构与分工
训练端与推理端分离
采用分布式架构,将计算密集型训练(PC端进行迁移学习模型训练)与实时推理(训练好的模型,传到Nano进行使用)拆分到不同平台:训练端负责模型参数收敛,Jetson Nano 负责现场推理与展示。
采样环境工程化约束
通过固定机位、控制背景、减少反光等手段提高采样一致性,从源头降低输入噪声对模型鲁棒性的影响。
视觉链路端到端打通
从图像采样、ROI 透视归一化、增强策略到分类输出形成完整闭环,确保训练数据分布与部署输入分布尽量一致。
边缘部署可运维化
在 Jetson 侧完成容器化运行、开机自启动、推理环境稳定性调优,保证课堂演示与竞赛实测过程持续可用。
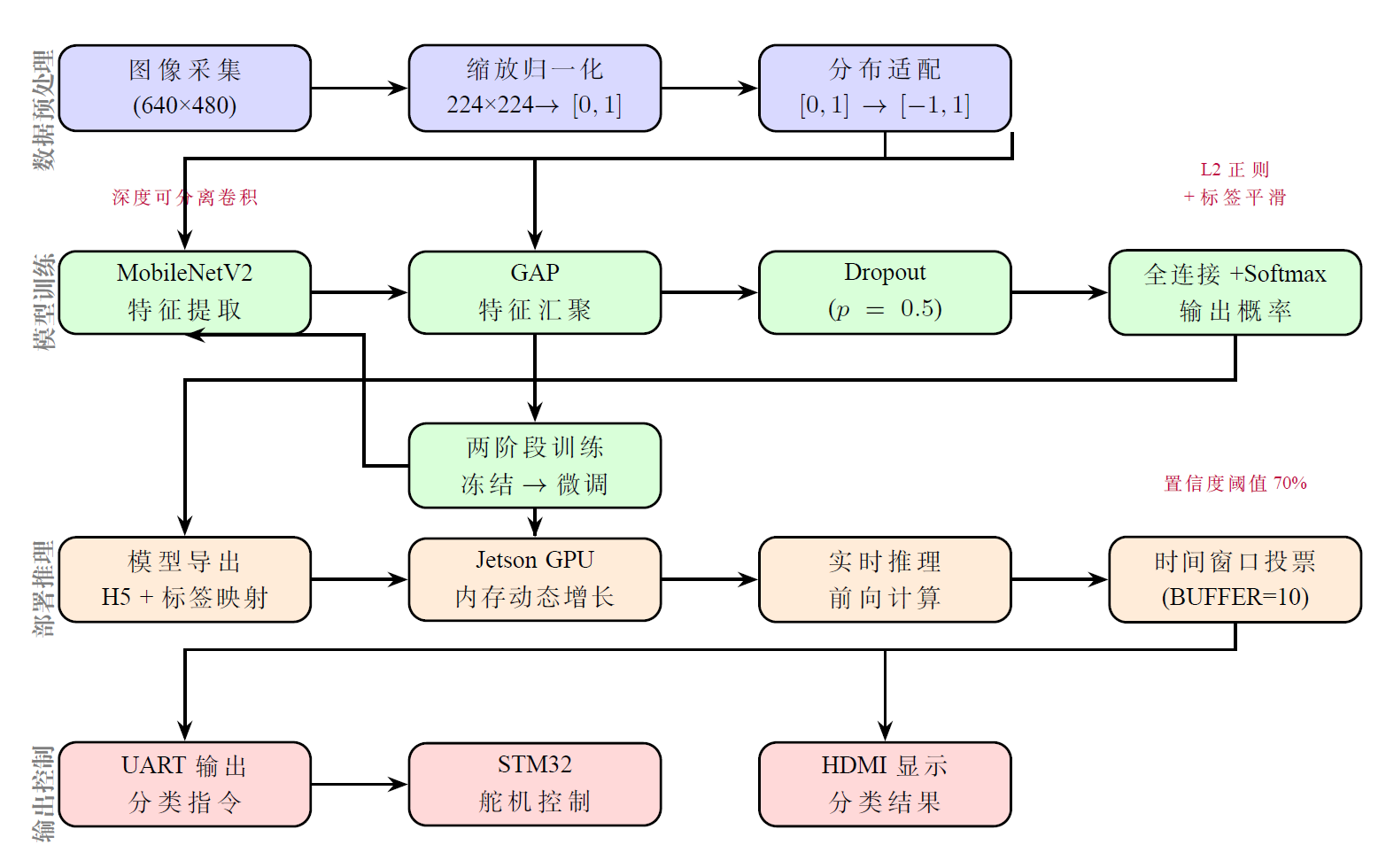
技术路线与分类输出
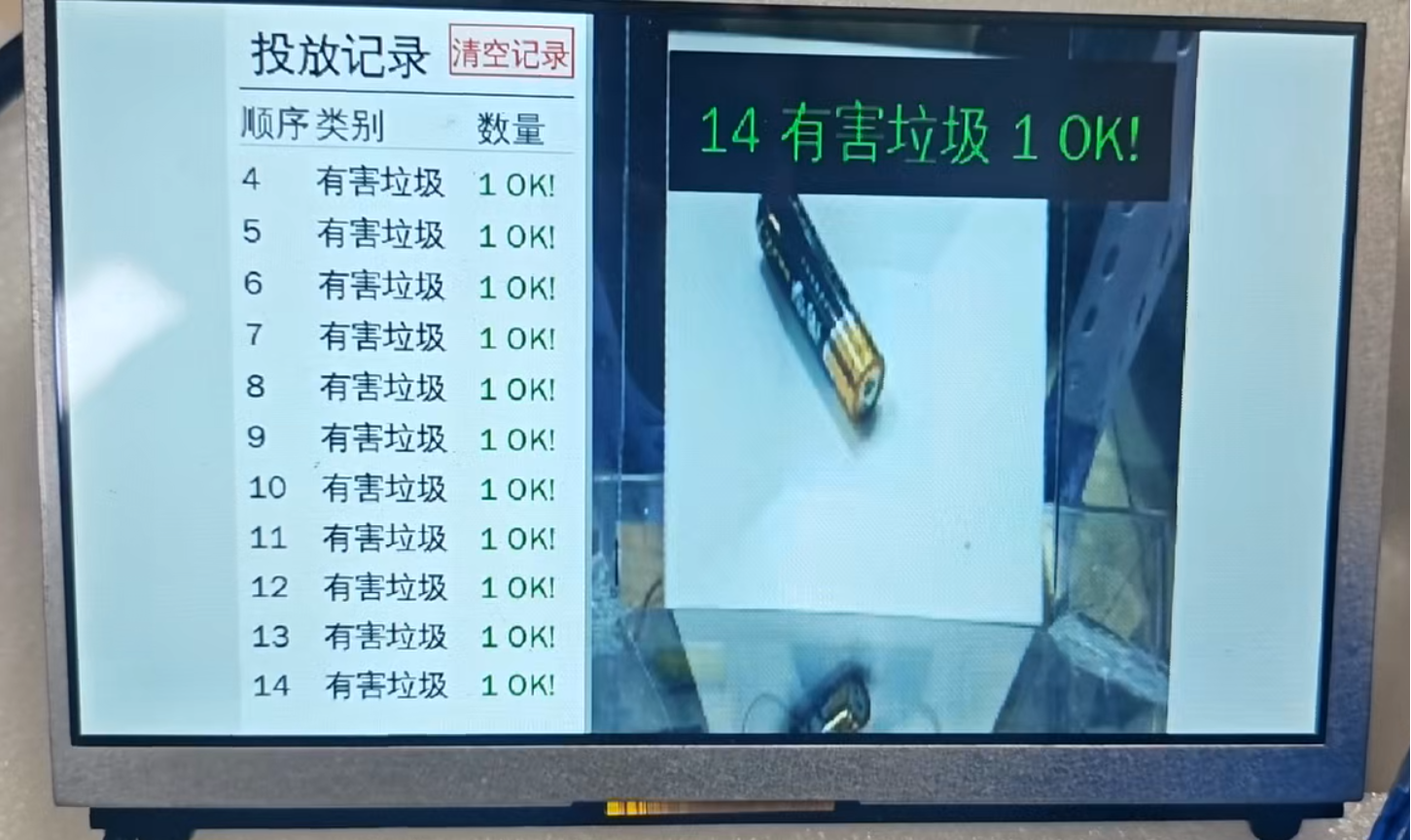
系统通过“图像采集 → 预处理/ROI 规范化 → MobileNetV2 推理 → HDMI 输出类别结果”的主流程运行。 左图为技术路线流程图,右图为装置端实时分类输出界面。
采样条件优化
在工程实践中,采样质量直接决定后续训练上限。项目通过在采样区域铺设黑色砂纸降低反光干扰,并持续迭代机位与背景设置, 使可回收物、有害垃圾、其他垃圾等类别在视觉特征上更易于区分,并且将装置内的视觉采样区域彻底封闭,照明由LED固定灯条提供,由此采样的照明条件不随场地迁移而变化。右下图展示了不当采样示例,对比可见干扰显著增加。




ROI归一化与数据增强
为统一训练与部署输入分布,工程将输入对齐到 224×224,并对原始高分辨率帧执行四点透视变换,提取标准化分类盘 ROI。
在此基础上,继续引入随机水平翻转、亮度/对比度/饱和度扰动、padding 后随机裁剪等增强策略,以提升模型对姿态与光照波动的鲁棒性。





迁移学习与部署结果
对于视觉模型训练,由于样本量的确较小,采用两阶段迁移学习的方式。阶段一是冻结骨干,只训练分类头;把MobileNetV2 的参数固定住(保留它从ImageNet 学到的通用图像特征,比如边缘、纹理),只训练分类头(全局池化、Dropout、全连接层)——相当于让分类头“学习如何把通用特征转化为5 类垃圾的判断结果”。该阶段学习率设为 10^-3,训练10 个epoch,收敛快且不易出错。阶段二是解冻高层,小学习率微调;当分类头训练稳定后,解冻MobileNetV2 的高层网络(冻结前100 层,只微调后面的层),让骨干网络适配垃圾图像的细粒度特征(比如塑料瓶的曲面、金属罐的反光)。此阶段学习率调小到10−5(更新步长极小),避免破坏MobileNetV2预训练的通用特征。
比赛现场考核类别为四类垃圾;工程代码中分类头设计为五类输出,其中额外一类为 NULL,用于承接垃圾分类装置空闲的场景。 最终离线验证准确率约为 98%,正式竞赛未知样本达到 7/8 识别成功。
Jetson Nano 侧完成了容器化环境部署(TensorFlow 2.7 Nvidia官方docker部署)、开机自启动、GPU 内存动态增长配置与运行稳定性调优,满足课堂演示与竞赛场景的连续运行需求。
课堂演示视频
若浏览器无法直接播放视频,可使用“新窗口打开”按钮。
新窗口打开 garbage-classroom-demo.mp4
PPT预览
若浏览器或网络环境无法直接预览 PPT,可使用“新窗口打开”按钮。